
Se hai ricevuto l'avviso ‘Indicizzato, anche se bloccato da robots.txt’ nella Google Search Console, vorrai risolverlo il prima possibile, poiché potrebbe influenzare la capacità delle tue pagine di posizionarsi nei Risultati delle Pagine dei Motori di Ricerca (SERPS).
Un file robots.txt è un file che si trova all'interno della directory del tuo sito web, che offre alcune istruzioni per i crawler dei motori di ricerca, come il bot di Google, su quali file dovrebbero e non dovrebbero visualizzare.
‘Indicizzato, anche se bloccato da robots.txt’ indica che Google ha trovato la tua pagina, ma ha anche trovato un'istruzione per ignorarla nel tuo file robots (il che significa che non apparirà nei risultati).
A volte questo è intenzionale, o a volte è accidentale, per una serie di motivi descritti di seguito, e può essere risolto.
Ecco uno screenshot della notifica:
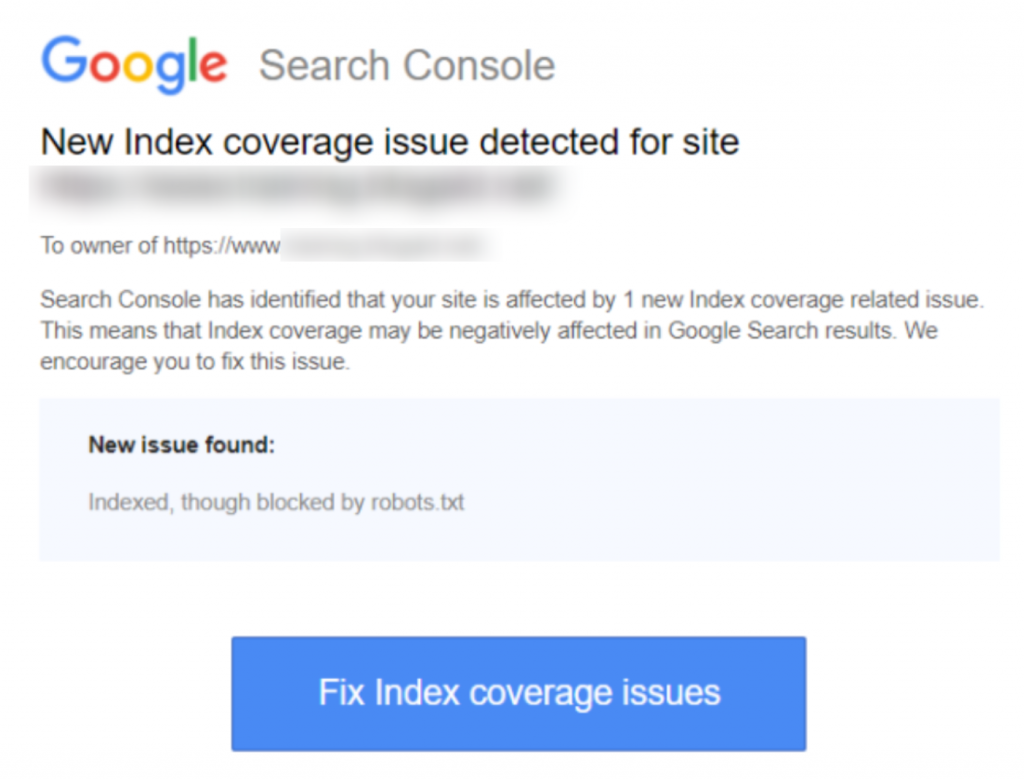
Identifica la o le pagine interessate o gli URL
Se hai ricevuto una notifica da Google Search Console (GSC), devi identificare la pagina o le pagine (URL) specifiche in questione.
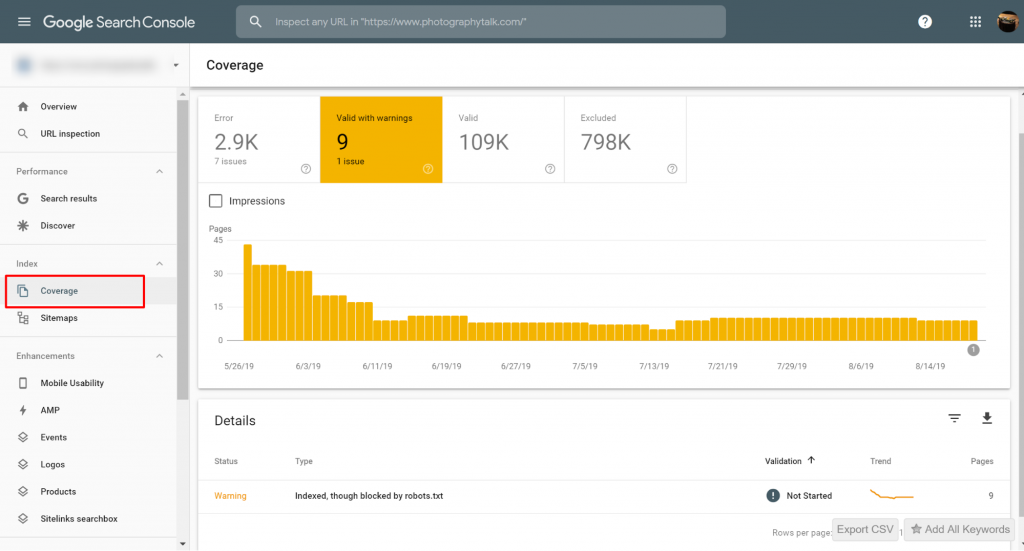
Puoi visualizzare le pagine con i problemi Indicizzate, ma bloccate da robots.txt su Google Search Console>>Copertura. Se non vedi l'etichetta di avviso, allora sei libero e senza problemi.
Un modo per testare il tuo robots.txt è tramite l'utilizzo del nostro tester di robots.txt. Potresti scoprire che va bene per te che ciò che viene bloccato rimanga 'bloccato'. Pertanto, non è necessario intraprendere alcuna azione.
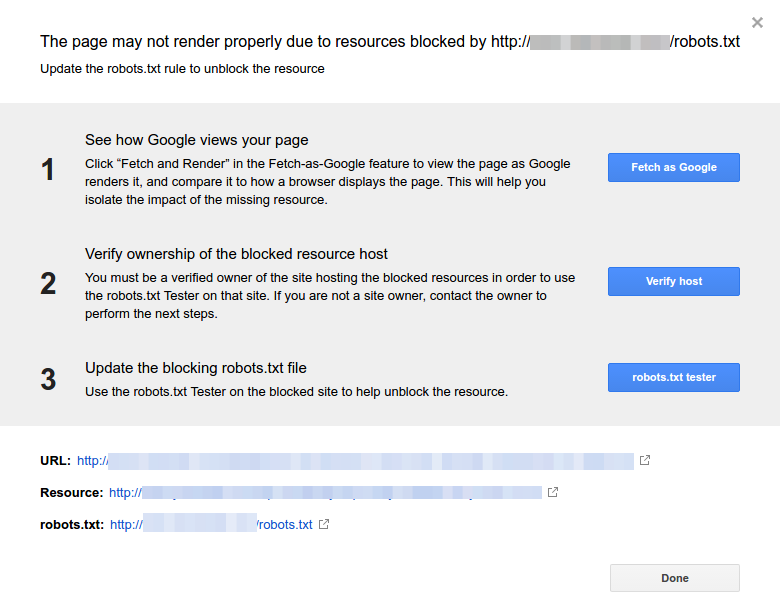
Puoi anche seguire questo link GSC. Dovrai poi:
- Apri l'elenco delle risorse bloccate e scegli il dominio.
- Fai clic su ogni risorsa. Dovresti vedere questo popup:
Identifica il motivo della notifica
La notifica può derivare da diversi motivi. Ecco i più comuni:
Ma prima di tutto, non è necessariamente un problema se ci sono pagine bloccate da robots.txt., Potrebbe essere stato progettato per motivi, come, lo sviluppatore che desidera bloccare pagine / categorie non necessarie o duplicati. Quindi, quali sono le discrepanze?
Formato URL errato
A volte, il problema potrebbe derivare da un URL che non è realmente una pagina. Ad esempio, se l'URL è https://www.seoptimer.com/?s=digital+marketing, devi sapere a quale pagina l'URL si risolve.
Se si tratta di una pagina che contiene contenuti significativi che vuoi davvero che i tuoi utenti vedano, allora devi cambiare l'URL. Questo è possibile sui Content Management Systems (CMS) come Wordpress dove puoi modificare lo slug di una pagina.
Se la pagina non è importante, o con il nostro esempio /?s=digital+marketing, si tratta di una query di ricerca dal nostro blog allora non c'è bisogno di correggere l'errore GSC.
Non fa alcuna differenza se è indicizzato o meno, dato che non è nemmeno un vero URL, ma una query di ricerca. In alternativa, puoi eliminare la pagina.
Pagine che dovrebbero essere indicizzate
Ci sono diverse ragioni per cui pagine che dovrebbero essere indicizzate non vengono indicizzate. Ecco alcune:
- Hai controllato le tue direttive robots? Potresti aver incluso direttive nel tuo file robots.txt che impediscono l'indicizzazione di pagine che dovrebbero essere effettivamente indicizzate, ad esempio, tag e categorie. I tag e le categorie sono URL effettivi sul tuo sito.
- Stai indirizzando Googlebot verso una catena di reindirizzamenti? Googlebot passa attraverso ogni link che può trovare e fa del suo meglio per leggere ai fini dell'indicizzazione. Tuttavia, se imposti una serie di reindirizzamenti multipli, lunghi e profondi, o se la pagina è semplicemente irraggiungibile, Googlebot smetterà di cercare.
- Implementato correttamente il link canonico? Un tag canonico viene utilizzato nell'intestazione HTML per indicare a Googlebot quale sia la pagina preferita e canonica in caso di contenuto duplicato. Ogni pagina dovrebbe avere un tag canonico. Ad esempio, hai una pagina che è stata tradotta in spagnolo. Dovrai auto-canonizzare l'URL spagnolo e vorrai canonizzare la pagina di ritorno alla tua versione inglese predefinita.
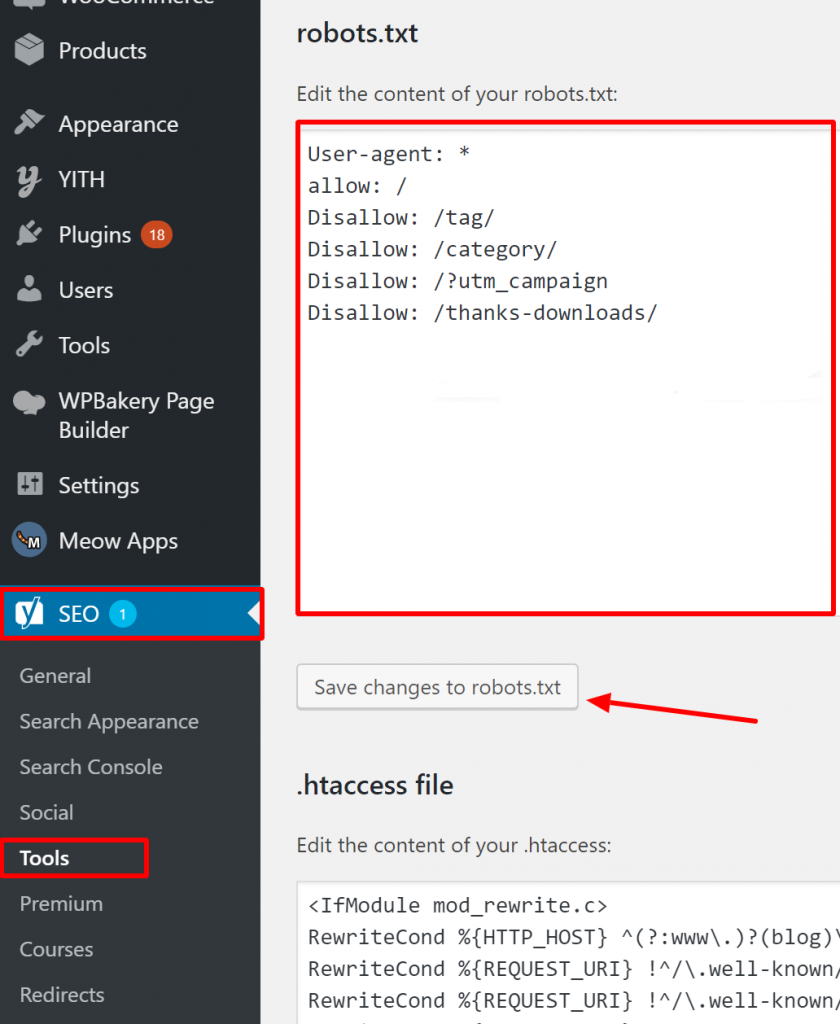
Come verificare che il tuo Robots.txt sia corretto su WordPress?
Per WordPress, se il tuo file robots.txt fa parte dell'installazione del sito, usa il Plugin Yoast per modificarlo. Se il file robots.txt che sta causando problemi si trova su un altro sito che non è il tuo, devi comunicare con i proprietari del sito e chiedere loro di modificare il loro file robots.txt.
Pagine che non dovrebbero essere indicizzate
Ci sono diverse ragioni per cui pagine che non dovrebbero essere indicizzate vengono indicizzate. Eccone alcune:
Le direttive Robots.txt che "dicono" che una pagina non dovrebbe essere indicizzata. Nota che devi permettere alla pagina con una direttiva 'noindex' di essere esplorata affinché i bot dei motori di ricerca "sappiano" che non dovrebbe essere indicizzata.
Nel tuo file robots.txt, assicurati che:
- La linea ‘disallow’ non segue immediatamente la linea ‘user-agent’.
- Non c'è più di un blocco ‘user-agent’.
- Caratteri Unicode invisibili - è necessario eseguire il file robots.txt attraverso un editor di testo che convertirà le codifiche. Questo rimuoverà qualsiasi carattere speciale.
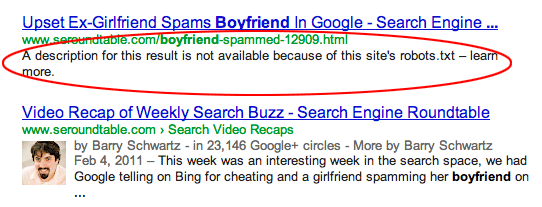
Le pagine sono collegate da altri siti. Le pagine possono essere indicizzate se sono collegate da altri siti, anche se escluse in robots.txt. In questo caso, tuttavia, solo l'URL e il testo dell'ancora appaiono nei risultati dei motori di ricerca. Ecco come vengono visualizzati questi URL nella pagina dei risultati del motore di ricerca (SERP):
 fonte dell'immagine Webmasters StackExchange
fonte dell'immagine Webmasters StackExchange
Un modo per risolvere il problema del blocco da parte di robots.txt è proteggere con password il file o i file sul tuo server.
In alternativa, elimina le pagine da robots.txt o utilizza il seguente meta tag per bloccare
loro:
<meta name="robots" content="noindex">
Vecchi URL
Se hai creato nuovi contenuti o un nuovo sito e hai utilizzato una direttiva ‘noindex’ in robots.txt per assicurarti che non venga indicizzato, o ti sei recentemente registrato a GSC, ci sono due opzioni per risolvere il problema bloccato da robots.txt:
- Dai tempo a Google di rimuovere eventualmente i vecchi URL dal suo indice
- Reindirizza i vecchi URL ai correnti con un 301 redirect
Nel primo caso, Google alla fine rimuove gli URL dal suo indice se tutto ciò che fanno è restituire 404 (il che significa che le pagine non esistono). Non è consigliabile utilizzare plugin per reindirizzare i tuoi 404. I plugin potrebbero causare problemi che possono portare a ricevere l'avviso ‘bloccato da robots.txt’ da parte di GSC.
File robots.txt virtuali
C'è la possibilità di ricevere notifiche anche se non si dispone di un file robots.txt. Questo perché i siti basati su CMS (Customer Management Systems), ad esempio WordPress, hanno file robots.txt virtuali. Anche i plug-in possono contenere file robots.txt. Questi potrebbero essere quelli che causano problemi sul tuo sito.
Questi virtuali robots.txt devono essere sovrascritti dal tuo file robots.txt. Assicurati che il tuo robots.txt includa una direttiva per consentire a tutti i bot dei motori di ricerca di esplorare il tuo sito. Questo è l'unico modo in cui possono indicare quali URL indicizzare o meno.
Ecco la direttiva che consente a tutti i bot di esplorare il tuo sito:
User-agent: *
Disallow: /
Significa "non vietare nulla".
In conclusione
Abbiamo esaminato l'avviso ‘Indexed, though blocked by robots.txt’, cosa significa, come identificare le pagine o gli URL interessati, così come il motivo dietro l'avviso. Abbiamo anche visto come risolverlo. Nota che l'avviso non equivale a un errore sul tuo sito. Tuttavia, non risolverlo potrebbe comportare che le tue pagine più importanti non vengano indicizzate, il che non è positivo per l'esperienza dell'utente.










